
There is a lot of work to be done to fully deploy the cloud application from scratch to production. See how to do it…
The concept has to be completely consistent with the Cloud architecture model.
It is assumed that only native SaaS services will be used without IaaS machines.
The approach to the entire architecture should be service-oriented, and fully scalable horizontally and vertically.
This article is about AWS infrastructure design and development. Cloud deployment requires DevOps preparation before.
Agenda
Architecture designing
Cloud infrastructure depends on the project architecture which is the starting point for designing Cloud deployment.
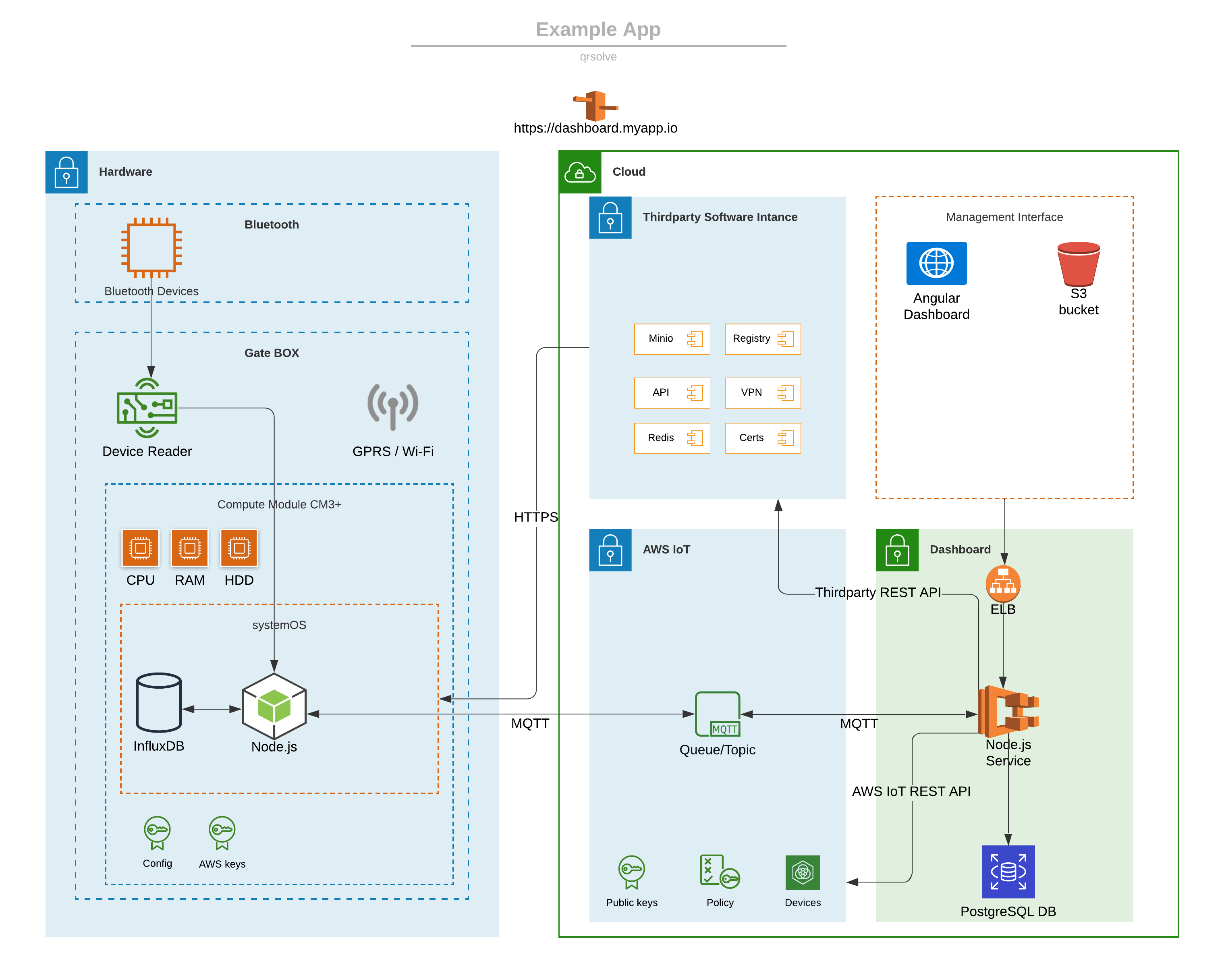
Cloud Resources
Based on the project design architecture, architects decide which Cloud resources should be used to build a Cloud project.

Internet infrastructure
Route 53
Our application uses two urls.
-
Web Simulator
-
API Endpoint

To connect DNS to CloudFront we need to redirect subdomains and point them to specific CloudFront distribution.
Route 53 can also act as an internal DNS for the ECS container. Service Discovery registers healthy IP addresses for containers in the local zone. This allows the application to communicate between internal services through aliases.
CloudFront

CloudFront provides CDN, certificate, cache, and other web features. CloudFront has separate distributions for all of our URLs like Backend API and UI Simulator. The distribution has its parameters like HTTP Headers etc. To redirect traffic there, two Origins were set up – one for the backend API and another for a frontend Web application.
The Backend API points to the backend load balancer and ECS and the frontend application points to the S3 bucket.
Path patterns and redirection definitions to a specific source are configured to ensure the appropriate behavior.
To configure the origin, security parameters, origin-destination and timeouts should be specified.
AWS Certificate Manager
Infrastructure has two public endpoints, so we are using two certificates.
-
HTTP/SSL Certificate - certificate for Backend API
-
HTTP/SSL Certificate - certificate for Frontend Simulator
High Availability infrastructure
Elastic Load Balancer

To balance internet traffic from API requests load balancer should be configured.
The load balancer is connected to the ECS container through the Target Group. The target group is a specific engine that is responsible for connecting load balancers with the ECS service. ECS automatically registers a new private IP with the target group.
Target Group
The Target group can register health checks where we can define HTTP path, timeout interval, and success code for health check service. For example, Spring Boot Actuator microservice can provide health check metrics.
Service Discovery
Middleware infrastructure
Task Definitions
We use task definitions to describe micro service behavior and required parameters.
The ECS cluster is configured to work with Fargate task definitions and services definitions. Tasks definitions are responsible for the whole configuration of the application for example Memory usage, CPU usage, Docker image address, port definitions, system variables, etc.
Tasks definition is automatically deployed by GitLab runner during CI/CD process. When task definition is ready to use, it is time for a new service.
Elastic Container Service

ECS is responsible for deploying and scaling Docker images in the AWS Cloud environment. Our implementation is configured to use one replica service. In a production environment, this will be scalable to multiple replicas.
Elastic Container Registry
As a Docker repository, we are using the ECR repository placed in AWS.
Storage infrastructure
Relational Database Service

It uses one of the RDS implementations, such as the MariaDB SQL database, as a data storage system.
S3 Simple Cloud Storage

There is one bucket inside the application to support the Charging Station Simulator frontend.
Lambda

Lambda uses Lambda to secure the static content for the charging station simulator.
Network infrastructure
VPC

One VPS is used the entire infrastructure. Traffic is shared between private (trusted) and public zones.
Subnets
We have designed 6 subnets, 3 for private zone and 3 for public zone.
Private Subnets
-
Subnet Private A
-
Subnet Private B
-
Subnet Private C
Public Subnets
-
Subnet Public A
-
Subnet Public B
-
Subnet Public C
ACL
We have one ACL table settings. Whole public traffic is off.
Internet Gateway
We use a single Internet Gateway to route traffic to the internet.
Parametrization
Parameters
AWS SSM Parameters are used by ECS services to parametrize the infrastructure.
Secret Manager
AWS SSM Parameters are used by ECS services to parametrize secured elements.
User management
IAM
-
ECS uses the AWS IAM role to perform the task
-
ECS uses the AWS IAM Policy for getting secret values from SSM
Security management
Security Groups
-
ELB security - security groups for load balancers
-
Lambda security - security groups for Lambda function
-
ECS security - security groups for Docker services
-
RDS security - security groups for MariaDB database
Logging
Log Groups
Each ECS service instance has its log group that stores system logs. It is very important to set up retention time to avoid keeping old logs.
Infrastructure creation
Now we are ready to deploy our Cloud infrastructure directly to a separated AWS sandbox account via CI/CD mechanisms.
Zero Down Time
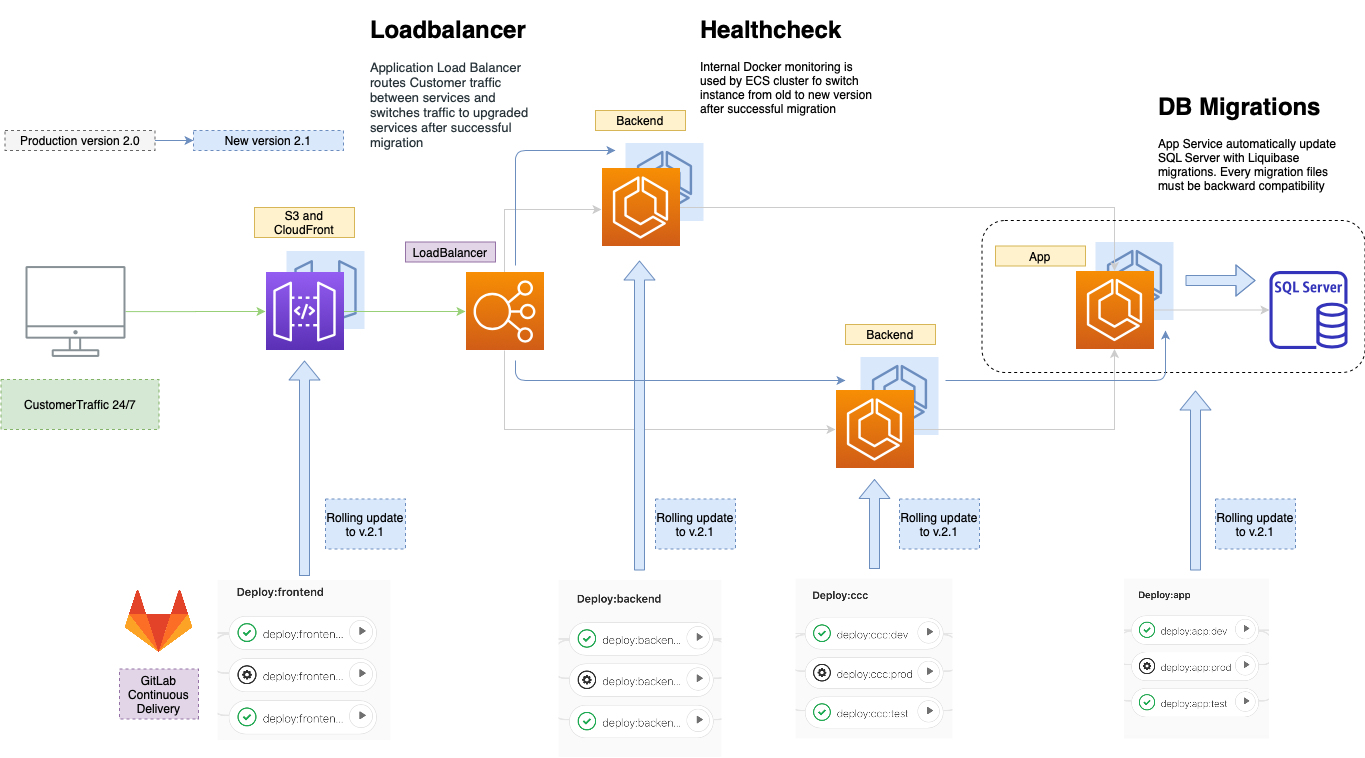
Failure prevention
Successful deployment is only the beginning of the entire migration to the cloud and system maintenance. We must be fully aware of possible failures in the Cloud system to ensure and configure appropriate prevention mechanisms. Finally, we should understand how to correct the possible effects of these problems.
Critical resources
Data Center
To determine the risk level, we need to know how AWS Data Center works with separate availability zones works.
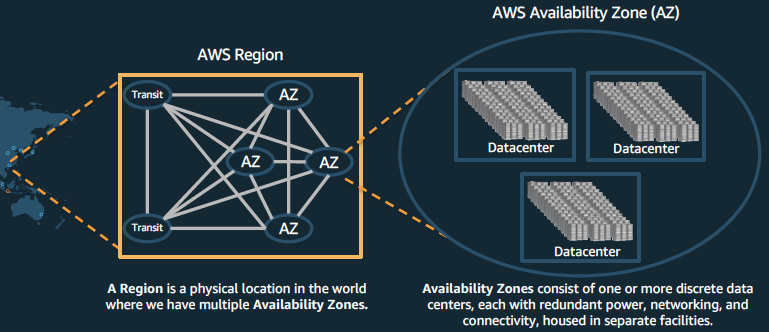
Data Center: Region
The application can be deployed in one of the AWS regions. The risk level of failure is very low. However, in case of failure, the impact on the application infrastructure cannot be determined.
Risk
-
Failure risk level:
very low -
Impact on the application: `not possible to determine
-
Effect:
system breakdown
Data Center: Availability Zone
Design
-
Fully isolated infrastructure with one or more data centers
-
Meaningful distance of separation
-
Unique power infrastructure
-
Many 100Ks of servers at scale
-
Data centers connected via fully redundant and isolated metro fiber
Risk
-
Failure risk level:
medium -
Impact on the application:
high -
Impact on S3: none
-
Impact on RDS:
high -
Impact on ECS: none
-
Effect:
possible system failure
Middleware infrastructure
ECS
Fargate cluster and tasks are available at a high level, preventing middleware unavailability.
Possible scenarios
-
The logic Compute instance is corrupted
-
Activity: LoadBalancer knows from health check about the crash and switches an instance to another
-
Mechanism: HA, Health check
-
-
The app has a performance issue or memory leak
-
Activity: Deploy the previous version of hotfix
-
Risk
-
Failure risk level: very low
-
Impact on the application: very high
-
AWS ECS SLA Level. Monthly Uptime Percentage: Less than
99.99%but equal to or greater than99.0%
Storage
RDS
The database has a mechanism that is configured to take snapshots every day.
Possible scenarios
-
Database is corrupted
Activity: Administrator restores database from snapshot Mechanism: Snapshot
Risk
-
Failure risk level: low
-
Software failure risk level:
medium -
Impact on the application:
very high -
Effect:
system failure -
AWS RDS SLA Level. Monthly Uptime Percentage: Less than
99.95%but equal to or greater than99.0%
S3
Data are stored in an S3 bucket. Mechanism: S3 replication, S3 versioning, MFA
To increase security and prevent data loss there is a versioning mechanism that can be enabled for the S3.
Possible scenarios
-
S3 file is lost or broken
-
Activity: Administrator restores the specific version of the file using versioning mechanism or restores file from an S3 backup
-
Mechanism: S3 replication, S3 versioning
-
-
S3 is inconsistent:
-
Activity: Administrator copies content from S3 backup
-
Mechanism: S3 replication
-
-
S3 was removed:
-
Activity: Administrator restores S3 bucket from corresponding backup S3 bucket
-
Mechanism: MFA
-
-
S3 and its backup is removed:
-
Activity: data is lost
-
Mechanism: MFA
-
Risk
-
Infrastructure failure risk level: very low
-
Software failure risk level:
medium -
Impact on the application:
very high -
Effect:
inconsistent data -
AWS S3 SLA Level. Monthly Uptime Percentage: Less than
99.9%but greater than or equal to99.0%
Recommendations
-
Prepare infrastructure audit across organization requirements
-
Prepare Security tests
-
Prepare performance tests
-
Configure AWS WAF service
-
Enable administration MFA option for S3 data buckets
-
Enable administration cross-account backuping
-
Specify sensitive data, if exist enable at rest encoding
Summary
A well-designed Cloud environment can be the foundation of your business model. The main thing is to do it the right way with the good and trusted standards, so it is not a waste of time and money.
 DevOps automation
DevOps automation